
Table of Contents

2025-04-03
Reliable Backups in Google Cloud with GKE and GitHubKubernetes Backup in Storage Buckets
We use not only Kubernetes, but also Cloud Storage, Cloud SQL, and GitHub Actions to run – and secure – our applications efficiently. In this article, we’ll show you how to implement a reliable Kubernetes backup strategy to protect your databases, media, and code from data loss.

Why are backups so important?
I probably don’t need to explain why backups are essential – at least I hope not. But beyond the obvious business goals, there are entire areas of corporate strategy dedicated to topics like backup and recovery – most notably Business Continuity Planning (BCP). BCP introduces terms like resilience and continuity, which define two critical metrics when it comes to IT systems. But it’s not just business planning that drives the need for backups – legal requirements also play a major role, especially in Europe. For example, the GDPR demands technical and organizational measures to ensure availability, which is directly linked to confidentiality and integrity. Similar rules apply under national advertising and data retention laws.
Recent history has shown us that backups and disaster recovery still don’t get the attention they deserve. It’s understandable – strategies that mitigate risk often don’t have a direct, visible impact on revenue. That makes them easy to push down the priority list.But companies that build resilience into their processes – whether it’s protection against human error or external threats like cyberattacks – will come out stronger in the long run. Because one thing is certain: the next outage is just a matter of time…
Let’s figure out your backup strategy together – book a free call.Overview of Backup Methods
Snapshots – The Quick and Easy Solution
Let’s start with some background: Depending on the specific requirements, the backup strategy must be adjusted accordingly. However, the foundation in every case is regular snapshots: these capture the entire dataset at the moment the snapshot is taken. Snapshots are generally easy to organize, but they consume the most storage space, while providing the fastest and most reliable form of recovery – as snapshots allow you to restart an IT service exactly as it was. The frequency of snapshot backups directly defines the maximum acceptable period for indirect data loss in the event of a disruption.
Differential Backups – Space-Saving, but More Complex
In addition to snapshots, differential backups can be created. These only save the data between a snapshot (also known as the “baseline”) and the moment the differential backup is made. Depending on the IT service involved, a differential backup can require significantly more effort in creation, management, and recovery. However, it saves storage space compared to a snapshot and thus reduces long-term costs.
Point-in-Time Backups – Maximum Flexibility
Point-in-Time Backups allow you to restore the system to any moment in the past. This backup method is considered the gold standard, though it might not always be unequivocally achievable in complex (distributed) IT systems. Every transaction that alters the system in any form is additionally secured at the time of confirmation. In practice, this backup strategy is the most demanding. It is very challenging to create, organize, and recover Point-in-Time Backups—the restoration process is both time-consuming and labor-intensive. This is because first a baseline (from a snapshot) must be restored, and then all transactions must be applied in a “replay” process in the correct order. If conditions outside the system boundaries occur that are no longer present at the time of recovery (for example, if data in another service have changed), the restoration process can also be disrupted.
Since we always need a solid plan for snapshot backups, this article focuses on how to create reliable backups using our tech stack: Kubernetes, Google Cloud Storage, Cloud SQL, and GitHub Actions. The goal is to secure everything necessary to restore the operation of an IT service from a backup.
Need hands-on help with your infrastructure? Reach out now.Where to Store It All: Cloud Storage
Let’s start at the end: where should your backups actually live? Cloud Storage is a great fit for many use cases. You can store and serve production data (like assets for a website – images, documents, etc.), use it as a transit medium between source and target systems, or archive data for the long term. In most scenarios, we’d say: this is where the backup journey ends. But depending on your setup, it might make sense to move data even further – to on-prem or enterprise storage for additional redundancy.
Setting Up All Necessary Backups
So, what exactly should be backed up? We usually talk about assets (images, videos, documents – all “movable” data outside of the database that isn’t part of the codebase), databases (persistent data stores), and your application’s source code. Beyond that, there are reproducible artifacts – things that can be generated based on existing data, like cached content or container images (e.g. Docker). These aren’t typically part of the backup strategy, either because they’re easy to rebuild or they’re already stored securely (container registries).
Storage Location for Backups: Using Cloud Storage
It’s also a good idea to back up your transactional cloud storage. Why? Because the bucket might not be configured for high availability (i.e. no redundant copies), or your BCP (yep, that again) requires protection against cloud provider outages. Luckily, most major cloud providers make this easy. In Google Cloud, for example, you can set up a one-click replication from one bucket to another using their ClickOps interface.
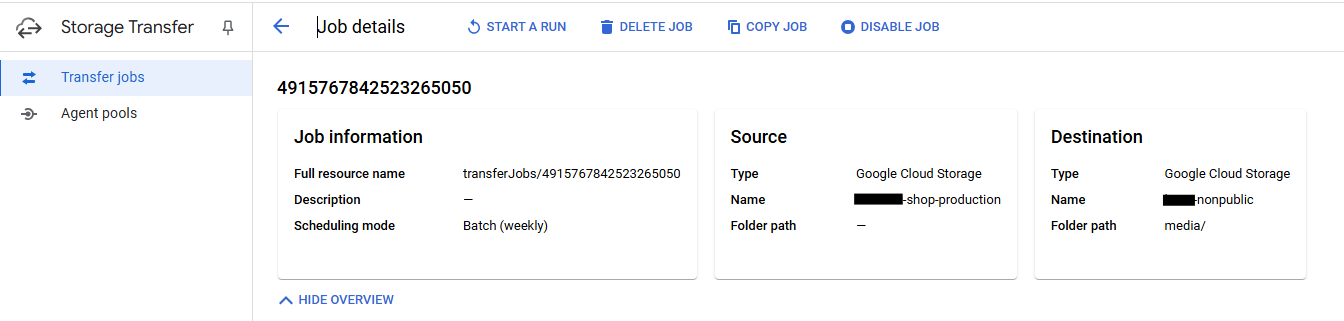
With Google Transfer, you can easily configure sources, targets, and execution schedules. There are also additional settings available – for example, how to handle deleted files.
Database Backup in Kubernetes with Cloud SQL
Things get a bit more interesting when it comes to Cloud SQL backups. In our experience, they’re not exactly “plug and play.” For a PostgreSQL-compatible database instance, you can’t simply create an SQL-Dump using built-in tools – not in Google Cloud, not in AWS. Why? We assume it's to make switching providers less convenient. Instead of generating a portable SQL dump, you’re stuck using the provider’s proprietary backup features. But lucky us – we’ve got a Kubernetes cluster that can access the database directly.
So what we need is a Kubernetes CronJob that connects to the database on a defined schedule and creates a snapshot. Good news: that part’s actually pretty straightforward.
Dockerfile for PostgreSQL Backup:
We use the official postgres image as a base. But the same approach works for most other (No)SQL databases – as long as there’s an official client available.
# --- Dockerfile ---
FROM postgres:latest-alpine
RUN apk add --update curl zip python3
RUN curl -sSL https://sdk.cloud.google.com | bash
ENV PATH $PATH:/root/google-cloud-sdk/bin
COPY backup.sh /
RUN chmod +x /backup.sh
This container image already comes with the psql client preinstalled. On top of that, we need a few additional tools to upload data to Google Cloud Storage, as well as the bash script that triggers the backup and handles the upload. Once everything is in place, the container image needs to be built and made accessible – for example, by pushing it to a container registry.
# --- backup.sh ---
#!/bin/bash
if [ ! -z $DEBUG ]; then
set -x
fi
# ENV variables for Postgres
HOSTNAME=$PG_HOSTNAME
PASSWORD=$PG_PASSWORD
USERNAME=$PG_USERNAME
DATABASE=$PG_DATABASE
OUTPUT_DIR="${PG_OUTPUT_DIR:-/pgbackup}"
NAME_PREFIX="${PG_PREFIX:-noprefix}"
ZIP_PASSWORD="${ZIP_PASSWORD:-setme}"
if [ $ZIP_PASSWORD = "setme" ]; then
ZIP_PASSWORD=`cat /etc/gcp/zip-password`
fi
GS_STORAGE_BUCKET="${GS_BUCKET:-nonpublic}"
gcloud auth activate-service-account --key-file /etc/gcp/sa_credentials.json
date1=$(date +%Y%m%d-%H%M)
mkdir $OUTPUT_DIR
filename=$OUTPUT_DIR"/"$date1"-$NAME_PREFIX-$DATABASE.pg"
PGPASSWORD="$PASSWORD" pg_dump -h "$HOSTNAME" -p 5432 -U "$USERNAME" "$DATABASE" -Fc > $filename
du -h $filename
zip -r --encrypt -P $ZIP_PASSWORD $filename".zip" $filename
du -h $filename".zip"
gcloud storage cp $filename".zip" "gs://"$GS_STORAGE_BUCKET"/database/"$NAME_PREFIX"/"
This example bash script is controlled entirely via environment variables. These are injected through the Kubernetes workload definition – typically using a Kubernetes secret. The script supports all the necessary parameters to:
- connect to a PostgreSQL database,
- request a SQL dump (in portable PostgreSQL format),
- encrypt that dump with a ZIP password and give it a traceable filename,
- and finally upload it to a Cloud Storage bucket.
Important: This example uses a service account to upload the backup to the -nonpublic Cloud Storage bucket. The setup of service accounts differs between cloud providers. In Google Kubernetes Engine, the service account token is stored in a Kubernetes secret and mounted into the Pod at /etc/gcp/sa_credentials.json).

You want to set up or optimize your backup strategy in Kubernetes the right way?
Automating Backups with a Kubernetes CronJob
With the following Kubernetes workload object, we can finally set up a scheduled job that reliably performs and stores the database backup. The syntax and structure of Kubernetes CronJobs can be found in the Kubernetes documentation.
apiVersion: batch/v1
kind: CronJob
metadata:
name: pg-backup
spec:
timeZone: "Europe/Berlin"
schedule: "45 1 * * *"
concurrencyPolicy: Forbid
successfulJobsHistoryLimit: 0
failedJobsHistoryLimit: 1
jobTemplate:
spec:
template:
spec:
# this secret is manually created holding 1) the service account key, and 2) the zip-password string
volumes:
- name: gcs-service-account
secret:
secretName: gcsbackup
containers:
- name: pgbackup
image: gcr.io/backup-images/pgbackup
imagePullPolicy: Always
command: ["/backup.sh"]
volumeMounts:
- mountPath: "/etc/gcp/"
name: gcs-service-account
readOnly: true
env:
- name: PG_DATABASE
valueFrom:
secretKeyRef:
name: shop-secret
key: DATABASE_NAME
- name: PG_USERNAME
valueFrom:
secretKeyRef:
name: shop-secret
key: DATABASE_USER
- name: PG_PASSWORD
valueFrom:
secretKeyRef:
name: shop-secret
key: DATABASE_PASSWORD
- name: PG_HOSTNAME
valueFrom:
secretKeyRef:
name: shop-secret
key: DATABASE_HOST
- name: PG_PREFIX
value: production
# - name: DEBUG
# value: "on"
restartPolicy: OnFailure
This way, all parameters – such as the backup cadence or database credentials – can be managed directly via Kubernetes. If a password rotation is needed, it’s just a matter of updating the corresponding Kubernetes secret.
Code Backup with GitHub Actions
It’s not just dynamic data that needs to be backed up – your codebase matters, too. Why? Because some statics (like media files embedded in the code, logos, small images, etc.) might need to be preserved, or your BCP includes a scenario where GitHub goes down. A GitHub outage may not immediately impact your app’s availability, but if it lasts longer, you’ll want to have a fallback in place to ensure continuity.
Fortunately, setting up a backup action for a repository is quick and easy.
# --- .github/workflows/code_backup.yaml ---
name: Backup Repo to Google Storage Bucket
on:
schedule:
- cron: '0 0 * * 0'
push:
branches:
- main
jobs:
backup_repo:
runs-on: ubuntu-latest
permissions:
contents: read
id-token: write
steps:
- name: Checkout Repo
uses: actions/checkout@v4
- id: auth
uses: google-github-actions/auth@v2
with:
credentials_json: ${{ secrets.GCP_CREDENTIALS }}
- name: Set up Cloud SDK
uses: google-github-actions/setup-gcloud@v2
- name: Zip and Upload
run: 'cd .. && zip --encrypt -P ${{ secrets.ZIP_PASSWORD }} -r our-backend.zip our-backend && gcloud storage cp our-backend.zip gs://-nonpublic/code/our-backend.zip'
Most major cloud providers already offer their own GitHub Actions to automatically upload data to a Cloud Storage bucket as part of a GitHub pipeline. In this example, the repository is checked out, encrypted as a ZIP file, and then uploaded to the designated Cloud Storage bucket.
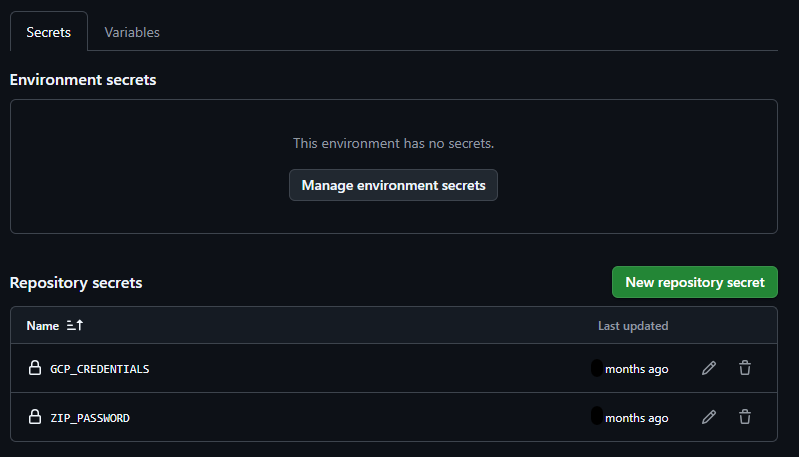
The environment variables used are injected into the context via Action Secrets.
Conclusion: A Kubernetes Backup Strategy for Maximum Reliability
Backups matter. In this article, I’ve shown you a straightforward way to set up snapshot backups using Kubernetes, GitHub, and a Cloud Storage bucket. These backups can be downloaded from Cloud Storage and stored on other media – ideally offline – for long-term retention and disaster recovery.
We deliberately left out the restore process in this article, but we plan to cover it in a follow-up.
We also think it would be useful to dive deeper into differential and point-in-time backups in the future.
But what about you? Got feedback, ideas, or experience with a similar setup? Let us know in the comments below!
Frequently Asked Questions
1. Why do I need a backup strategy for Kubernetes?
Kubernetes environments are dynamic and consist of many moving parts. Database entries, code changes, and media files can be lost at any time – due to misconfigurations, system failures, or cyberattacks. A well-thought-out backup strategy ensures you can quickly restore your applications and data.
2. How often should I back up my database?
That depends on your specific needs. A snapshot-based strategy with daily backups is a good starting point for many applications. If your data changes frequently, you should consider differential or point-in-time backups. Kubernetes CronJobs help you automate these processes efficiently.
3. Where should I store my backups?
Cloud storage is one of the best options for secure and scalable backups. Google Cloud Storage, AWS S3, and Azure Blob Storage offer high availability and built-in encryption. Alternatively, you can store backups on local servers or external media to add an extra layer of security.
4. Can I use GitHub Actions to automatically back up my code?
Yes! GitHub Actions can be used to automatically back up your code to a cloud storage bucket. This protects you in case of a GitHub outage or accidental deletions. Our article includes a sample workflow file for your repository.















