
20.11.2024
Dynamic Workload Scaling: A Look at the Horizontal Pod Autoscaler.Kubernetes Scaling in the Google Cloud
In this article, we discuss the possibility of scaling Kubernetes workloads in the Google Cloud simply and sustainably.

Scaling the API - too much and too little
Kubernetes already allows scaling workloads in a simple way. For this article, a stateless application is assumed - a simple REST API.
This is in the form of a Deployment with 4 Replicas (each 125 mCPU and 250 MiB Memory) in the GKE Autopilot Cluster.
Problem Statement: At night, these 4 Replicas run almost without load. During the day, these partially do not suffice.
Solution: Automatic scaling of services based on their load.
In the worst case, the applications are killed during high load - because they consume too much memory.
How much CPU or working memory do my pods need?
Before scaling is configured, it is important to find out - what are actually typical metrics for the behavior of the to-be-scaled application. Does it consume a lot of CPU or a lot of working memory? Is there another metric that provides insight into the load (e.g. Request Queue-Length)?
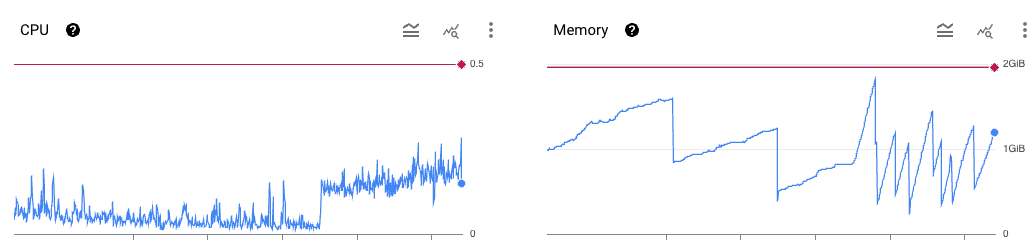
A quick look at the Google Cloud Dashboards of our REST API shows that working memory fluctuates and CPU has a relatively constant load from a certain point in time. The blue line shows the actual load, the red line the limits. The working memory seems clearly more volatile and closer to its limits - for scaling our application in Kubernetes, memory will be used as a basis.
Now it is clear which metric is being used, but not yet what the necessary parameters are. The memory load rarely falls below 250 MiB, which means at least 2 pods should be constantly available. We rarely, but reliably, approach the capacity limit of the currently 4 available replicas. So we take with some buffer a maximum of 6 replicas as highest load.
Note: Strongly fluctuating working memory load indicates problems in the application. In this case, a memory leak of a dependency that cannot be changed.
Scaling in Kubernetes: the Horizontal Pod Autoscaler
The Google Cloud allows both vertical and horizontal scaling of workloads. Vertical scaling means that the available resources (CPU, Memory) of Pods are scaled. Horizontal scaling creates and removes entire Pods of the same Deployment.
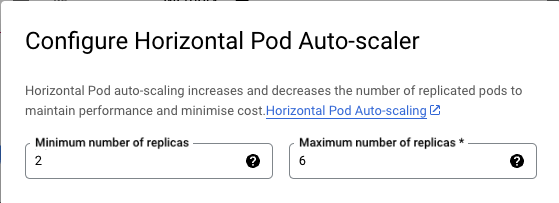
The basic parameters are quickly created - the minimum and maximum of the API scaling is handled with the following 2 fields:

We can also dynamically scale your apps.
But what is now the baseline for scaling itself? It's simple - for our example, an "ideal load" per pod is set. The limit of each pod is set at 250 MB. With a load of 80% or 200 MB (with some buffer), we reach the load limit of the service and need a new instance.

Since the defined minimum is 2 pods - as soon as the memory load in the average exceeds 400 MB, a further pod will be scaled. If this is then again fallen below, the Horizontal Pod Autoscaler (HPA) also removes this again.
For all Kubernetes Experts - of course, the HPA can also be defined via Kubernetes Resources and thus stored as a configuration in the cluster - the typical DevOps approach.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: store-autoscale
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: store-autoscale
minReplicas: 2
maxReplicas: 6
metrics:
- resource:
name: memory
target:
averageValue: 200
type: AverageValue
Conclusion
With a few clicks - or even a simple Kubernetes resource - costs can be saved and the load peaks of the REST API can be easily handled.
Do you have questions or an opinion? With your GitHub account you can let us know...
Here are a few articles that you might also find interesting:

How to: Custom configurations for ingress-nginx with kustomize
Ingress-nginx is one of the most popular ingress controllers for Kubernetes. In this blog post, we show how one can adjust the ingress-nginx K8s resources and easily persist them using kustomize. This makes installation and updates simpler and less error-prone.

StrongSwan VPN in Kubernetes: Securely Integrate External Services
In some cases, a VPN connection to an external service is needed - which can be tricky with Kubernetes. In this article, we show how to set up an IPsec tunnel with StrongSwan. From Kubernetes to an external service using Nginx as a reverse proxy. The setup is clearly structured, easily maintainable, and dynamically distinguishes between staging and production environments.

Kubernetes Backup in Storage Buckets
We use not only Kubernetes, but also Cloud Storage, Cloud SQL, and GitHub Actions to run – and secure – our applications efficiently. In this article, we’ll show you how to implement a reliable Kubernetes backup strategy to protect your databases, media, and code from data loss.

Gefyra Roadmap 2025
Gefyra has big plans for 2025! From improved developer tools to new integrations and better performance – the roadmap is packed with exciting updates. In this blog post, we’ll walk you through what’s coming and how Gefyra aims to keep revolutionizing development and debugging in Kubernetes. Stick around for a glimpse into the next chapter!

Cost Optimization of an Azure Kubernetes Cluster
Cloud resources are powerful and practical, but expensive - especially Kubernetes clusters. In this blog post, we show how we successfully implemented Azure Kubernetes Service Cost Optimization in a existing project. We present strategies, tools, and best practices that helped reduce AKS costs without compromising performance.

Efficient Runtimes with KEDA: Dynamic Autoscaling for Kubernetes Clusters
Kubernetes is performance-strong, but without optimized operating times, unnecessary resources and costs can arise. KEDA (Kubernetes Event Driven Autoscaling) enables dynamically scaling workloads and pausing them outside defined operating times. In this blog post, we show how you can adapt your cluster to work times – for more efficiency and reduced hosting costs.